В конце прошлого года компания Citrix анонсировала скорую доступность новых версий своих платформ для виртуализации и доставки приложений и десктопов - XenApp 7.7 и XenDesktop 7.7. На днях же эти продукты стали доступны для загрузки. О прошлых версиях данных решений мы писали вот тут.
Давайте посмотрим на новые возможности Cirtix XenApp 7.7 и XenDesktop 7.7:
1. Функционал зон (zones).
Эти возможности позволяют оптимизировать типовую инфраструктуру географически распределенных филиалов. Можно использовать одну первичную зону (Primary Zone), на которой есть единая база данных SQL Server (Site Database) и общие компоненты инфраструктуры Citrix, а остальные зоны (Satellite Zones) получают конфигурации из центральной зоны по WAN, но запросы виртуальных ПК к контроллерам исполняются локально.
В данном случае сайт получается один, но в него входит несколько логических зон (например, датацентры в разных городах). Более подробно проблематика рассмотрена на видео ниже, а также в этой и этой статьях.
2. Улучшенные настройки баз данных.
Теперь при создании сайта XenDesktop/XenApp можно указать различные места размещения баз данных для объектов Site, Logging и Monitoring. Также компоненты Delivery Controllers можно создавать не только при создании сайта, но и позже. Более подробная информация приведена вот тут.
3. Функции Application limits.
Теперь можно задавать лимиты для доставляемых с помощью XenApp и XenDesktop приложений. Например, можно ограничить число пользователей одновременно использующих данное приложение (ограничения у него могут быть как технические, так и лицензионные) или ограничить число запущенных экземпляров приложения на пользователя.
4. Улучшенные нотификации об изменении статуса виртуальных машин.
Теперь можно настроить многократные нотификации затронутым виртуальным машинам о следующих событиях, которые произойдут в скором времени:
Апдейт виртуальных машин в Machine Catalog с использованием нового мастер-образа.
Перезагрузка машин в рамках Delivery Group для применения настроек.
Сообщения можно повторять каждые 5 минут за 15 минут до начала выполнения действий.
5. Поддержка API для перемещаемых сессий.
По умолчанию сессия пользователя перемещается с ним от девайса к девайсу, при этом он может пользоваться приложениями на любом устройстве. Теперь обновленный PowerShell SDK позволяет учитывать этот момент при работе через API. Ранее эта фича была экспериментальной, а теперь стала полноценной.
6. Поддержка API для развертывания ВМ из шаблонов.
Теперь виртуальные машины из шаблонов на гипервизор можно развертывать автоматизированно, используя PowerShell SDK.
7. Поддержка обновленных программных компонентов.
Теперь при установке Delivery Controller по умолчанию развертывается SQL Server 2012 Express SP2 (SP1 больше не поддерживается), также обновлены 32 и 64-битные версии Microsoft Visual C++ 2013, 2010 SP1 и 2008 SP1. Citrix Studio или VDA для Windows Desktop OS можно развернуть на Windows 10. Citrix Receiver for Mac и Citrix Receiver for Linux теперь доступны только с сайта Citrix.
Теперь звонки и видео звонки будут намного качественнее и стабильнее за счет обновленного RealTime Optimization Pack.
10. Интеграция с Azure.
Теперь через Machine Creation Services (MCS) можно быстро и просто создать виртуальные машины в облаке Microsoft Azure. Также Citrix Provisioning Services поддерживается онпремизное развертывание виртуальных ПК на основе Windows 10.
11. Запись сессий в VDI-инфраструктуре.
Теперь можно использовать Session Recording for VDI для записи сессии пользователя виртуального ПК (администратор может так записывать обучающее видео для пользователя или, наоборот, попросить его записать возникшую проблему).
Более подробно о фичах нового релиза можно прочитать в этой статье (там же и про объявленные возможности следующей версии Citrix XenApp 7.8 и XenDesktop 7.8).
Вчера мы писали про режим воспроизведения, который можно использовать для утилиты esxtop, предназначенной мониторинга производительности хост-серверов VMware ESXi. А сегодня предлагаем вам скачать постер "vSphere 6 ESXTOP quick Overview for Troubleshooting", в котором приведена основная информация для начала работы с esxtop, а также базовые приемы по решению возникающих в виртуальной инфраструктуре проблем с производительностью. Также стоит заглянуть вот в эту и эту заметку на нашем сайте.
Постер можно повесить в админской или серверной, где часто приходится работать с консолью серверов ESXi:
Интересную новость мы обнаружили вот тут. Оказывается утилита esxtop может работать в режиме повтора для визуализации данных о производительности, собранных в определенный период времени (многие администраторы знают это, но далеко не все). Это позволит вам собрать данные о производительности хоста, например, ночью, а в течение рабочего дня проанализировать аномальное поведение виртуальной инфраструктуры VMware vSphere. Называется этот режим replay mode.
Для начала запустите следующую команду для сбора данных на хосте VMware ESXi:
Корпоративный IaaS-провайдер «ИТ-ГРАД» в качестве облачной площадки выбрал один из крупнейших московских дата-центров DataSpace. В чем его основные преимущества и чем выбранный ЦОД отличается от всех остальных? И правда, чем же DataSpace так приглянулся компании «ИТ-ГРАД», ведь сегодня на рынке ЦОД немало игроков?
Вебинар пройдет 20 января в 22-00 по московскому времени. Участие бесплатное.
На вебинаре речь пойдет об унифицированном решении на базе серверов Dell, гипервизора Microsoft Hyper-V, ПО для хранилищ StarWind Virtual SAN, резервного копирования Veeam Backup and Replication, а также средств управления 5nine Hyper-V Manager (подробнее - тут).
Приходите на вебинар, посмотрите живую демонстрацию совместной работы перечисленных компонентов и узнайте, каким образом с помощью данного комплекса вы сможете существенно сэкономить финансовые ресурсы при условии решения текущих задач по надежному хранению виртуальных машин.
Мы часто пишем о том, что снапшоты в VMware vSphere - это плохо (за исключением случаев, когда они используются для горячего резервного копирования виртуальных машин и временного сохранения конфигурации ВМ перед обновлением).
Однако их использование в крупных инфраструктурах неизбежно. Рано или поздно возникает необходимость удаления/консолидации снапшотов виртуальной машины (кнопка Delete All в Snapshot Manager), а процесс этот достаточно длительный и требовательный к производительности хранилищ, поэтому неплохо бы заранее знать, сколько он займет.
Напомним, что инициирование удаления снапшотов в vSphere Client через функцию Delete All приводит к их удалению из GUI сразу же, но на хранилище процесс идет долгое время. Но если в процесс удаления возникнет ошибка, то файлы снапшотов могут остаться на хранилище. Тогда нужно воспользоваться функцией консолидации снапшотов (пункт контекстного меню Consolidate):
О процессе консолидации снапшотов мы также писали вот тут. Удаление снапшотов (как по кнопке Delete All, так и через функцию Consolidate) называется консолидацией.
Сначала посмотрим, какие факторы влияют на время процесса консолидации снапшотов виртуальной машины:
Размер дельта-дисков - самый важный параметр, это очевидно. Чем больше данных в дельта-диске, тем дольше их нужно применять к основному (базовому) диску.
Количество снапшотов (число дельта-файлов) и их размеры. Чем больше снапшотов, тем больше метаданных для анализа перед консолидацией. Кроме того, при нескольких снапшотах консолидация происходит в несколько этапов.
Производительность подсистемы хранения, включая FC-фабрику, Storage Processor'ы хранилищ, LUN'ы (число дисков в группе, тип RAID и многое другое).
Тип данных в файлах снапшотов (нули или случайные данные).
Нагрузка на хост-сервер ESXi при снятии снапшота.
Нагрузка виртуальной машины на подсистему хранения в процессе консолидации. Например, почтовый сервер, работающий на полную мощность, может очень долго находится в процессе консолидации снапшотов.
Тут надо отметить, что процесс консолидации - это очень требовательный к подсистеме ввода-вывода процесс, поэтому не рекомендуется делать это в рабочие часы, когда производственные виртуальные машины нагружены.
Итак, как можно оценивать производительность процесса консолидации снапшотов:
Смотрим на производительность ввода-вывода хранилища, где находится ВМ со снапшотами.
Для реализации этого способа нужно, чтобы на хранилище осталась только одна тестовая виртуальная машина со снапшотами. С помощью vMotion/Storage vMotion остальные машины можно с него временно убрать.
1. Сначала смотрим размер файлов снапшотов через Datastore Browser или с помощью следующей команды:
ls -lh /vmfs/volumes/DATASTORE_NAME/VM_NAME | grep -E "delta|sparse"
2. Суммируем размер файлов снапшотов и записываем. Далее находим LUN, где размещена наша виртуальная машина, которую мы будем тестировать (подробнее об этом тут).
3. Запускаем команду мониторинга производительности:
# esxtop
4. Нажимаем клавишу <u> для переключения в представление производительности дисковых устройств. Для просмотра полного имени устройства нажмите Shift + L и введите 36.
5. Найдите устройство, на котором размещен датастор с виртуальной машиной и отслеживайте параметры в колонках MBREAD/s и MBWRTN/s в процессе консолидации снапшотов. Для того, чтобы нужное устройство было вверху экрана, можно отсортировать вывод по параметру MBREAD/s (нажмите клавишу R) or MBWRTN/s (нажмите T).
Таким образом, зная ваши параметры производительности чтения/записи, а также размер снапшотов и время консолидации тестового примера - вы сможете оценить время консолидации снапшотов для других виртуальных машин (правда, только примерно того же профиля нагрузки на дисковую подсистему).
Смотрим на производительность конкретного процесса консолидации снапшотов.
Это более тонкий процесс, который можно использовать для оценки времени снапшота путем мониторинга самого процесса vmx, реализующего операции со снапшотом в памяти сервера.
1. Запускаем команду мониторинга производительности:
# esxtop
2. Нажимаем Shift + V, чтобы увидеть только запущенные виртуальные машины.
3. Находим ВМ, на которой идет консолидация.
4. Нажимаем клавишу <e> для раскрытия списка.
5. Вводим Group World ID (это значение в колонке GID).
6. Запоминаем World ID (для ESXi 5.x процесс называется vmx-SnapshotVMX, для ранних версий SnapshotVMXCombiner).
7. Нажимаем <u> для отображения статистики дискового устройства.
8. Нажимаем <e>, чтобы раскрыть список и ввести устройство, на которое пишет процесс консолидации VMX. Что-то вроде naa.xxx.
9. Смотрим за процессом по World ID из пункта 6. Можно сортировать вывод по параметрам MBREAD/s (клавиша R) или MBWRTN/s (клавиша T).
10. Отслеживаем среднее значение в колонке MBWRTN/s.
Это более точный метод оценки и его можно использовать даже при незначительной нагрузке на хранилище от других виртуальных машин.
Напомним, что Veeam Availability Suite - это самое продвинутое в отрасли решение для всесторонней защиты данных средствами резервного копирования и репликации, а также набор продуктов для управления и мониторинга виртуальной среды. По-сути, это все что нужно, кроме самой платформы VMware vSphere или Microsoft Hyper-V, чтобы организовать виртуальный датацентр с непрерывной доступностью сервисов в виртуальных машинах.
Приведем ниже основные новые возможности Veeam Availability Suite v9, касающиеся его основного компонента - Veeam Backup and Replication 9:
1. Интеграция с технологией EMC Storage Snapshots в Veeam Availability Suite v9.
Многие пользователи Veeam Backup and Replication задавали вопрос, когда же будет сделана интеграция с дисковыми массивами EMC. Теперь она добавлена для СХД линеек EMC VNX и EMC VNXe.
Интеграция с хранилищами EMC означает поддержку обеих техник - Veeam Explorer for Storage Snapshots recovery и Backup from Storage snapshots, то есть можно смотреть содержимое снапшотов уровня хранилища и восстанавливать оттуда виртуальные машины (и другие сущности - файлы или объекты приложений), а также делать бэкап из таких снапшотов.
Иллюстрация восстановления из снапшота на хранилище EMC:
Иллюстрация процесса резервного копирования (Veeam Backup Proxy читает данные напрямую со снапшота всего тома, сделанного на хранилище EMC):
Более подробно об этих возможностях можно почитать в блоге Veeam.
2. Veeam Cloud Connect - теперь с возможностью репликации.
Как вы помните, в прошлом году компания Veeam выпустила средство Veeam Cloud Connect, которое позволяет осуществлять резервное копирование в облако практически любого сервис-провайдера. Теперь к этой возможности прибавится еще и возможность репликации ВМ в облако, что невероятно удобно для быстрого восстановления работоспособности сервисов в случае большой или маленькой беды:
Кстати, Veeam Cloud Connect инкапуслирует весь передаваемый трафик в один-единственный порт, что позволяет не открывать диапазоны портов при соединении с инфраструктурой сервис-провайдера. Очень удобно.
При восстановлении в случае аварии или катастрофы основного сайта, возможно не только полное восстановление инфраструктуры, но и частичное - когда часть продуктивной нагрузки запущено на основной площадке, а другая часть (например, отказавшая стойка) - на площадке провайдера. При этом Veeam Backup обеспечивает сетевое взаимодействие между виртуальными машинами обеих площадок за счет встроенных компонентов (network extension appliances), которые обеспечивают сохранение единого пространства адресации.
Ну а сервис-провайдеры с появлением репликации от Veeam получают в свои руки полный спектр средств для организации DR-площадки в аренду для своих клиентов:
Более подробно об этой возможности можно прочитать в блоге Veeam по этой ссылке.
3. Прямой доступ к хранилищам NAS/NFS при резервном копировании.
Veeam Availability Suite v9 поддерживает прямой доступ к хранилищам NAS/NFS при резервном копировании. Раньше пользователи NFS-массивов чувствовали себя несколько "обделенными" в возможностях, так как Veeam не поддерживал режим прямой интеграции с таким типом дисковым массивов, как это было для блочных хранилищ.
Теперь же появилась штука, называемая Direct NFS, позволяющая сделать резервную копию ВМ по протоколам NFS v3 и новому NFS 4.1 (его поддержка появилась только в vSphere 6.0), не задействуя хост-сервер для копирования данных:
Специальный клиент NFS (который появился еще в 8-й версии) при включении Direct NFS получает доступ к файлам виртуальных машин на томах, для которых можно делать резервное копирование и репликацию без участия VMware ESXi, что заметно повышает скорость операций.
Кроме этого, была улучшена поддержка дисковых массивов NetApp. В версии 9 к интеграции с NetApp добавилась поддержка резервного копирования из хранилищ SnapMirror и SnapVault. Теперь можно будет создавать аппаратные снимки (с учетом состояния приложений) с минимальным воздействием на виртуальную среду, реплицировать точки восстановления на резервный дисковый массив NetApp с применением техник SnapMirror или SnapVault, а уже оттуда выполнять бэкап виртуальных машин.
При этом процесс резервного копирования не отбирает производительность у основной СХД, ведь операции ввода-вывода происходят на резервном хранилище:
Ну и еще одна полезная штука в плане поддержки аппаратных снимков хранилищ от Veeam. Теперь появится фича Sandbox On-Demand, которая позволяет создать виртуальную лабораторию, запустив виртуальные машины напрямую из снапшотов томов уровня хранилищ. Такая лаборатория может быть использована как для проверки резервных копий на восстановляемость (сразу запускаем ВМ и смотрим, все ли в ней работает, после этого выключаем лабораторию, оставляя резервные копии неизменными), так и для быстрого клонирования наборов сервисов (создали несколько ВМ, после чего создали снапшот и запустили машины из него). То есть, можно сделать как бы снимок состояния многомашинного сервиса (например, БД-сервер приложений-клиент) и запустить его в изолированном окружении для тестов, ну или много чего еще можно придумать.
Вот здесь вы можете узнать больше подробностей об этой возможности в блоге Veeam.
Очередная функция Get-VMHostFirmwareVersion моего PowerCLI модуля для управления виртуальной инфраструктурой VMware Vi-Module.psm1 поможет вам узнать версию и дату выпуска Firmware ваших серверов ESXi. Для большей гибкости и удобства в использовании, функция написана в виде PowerShell-фильтра.
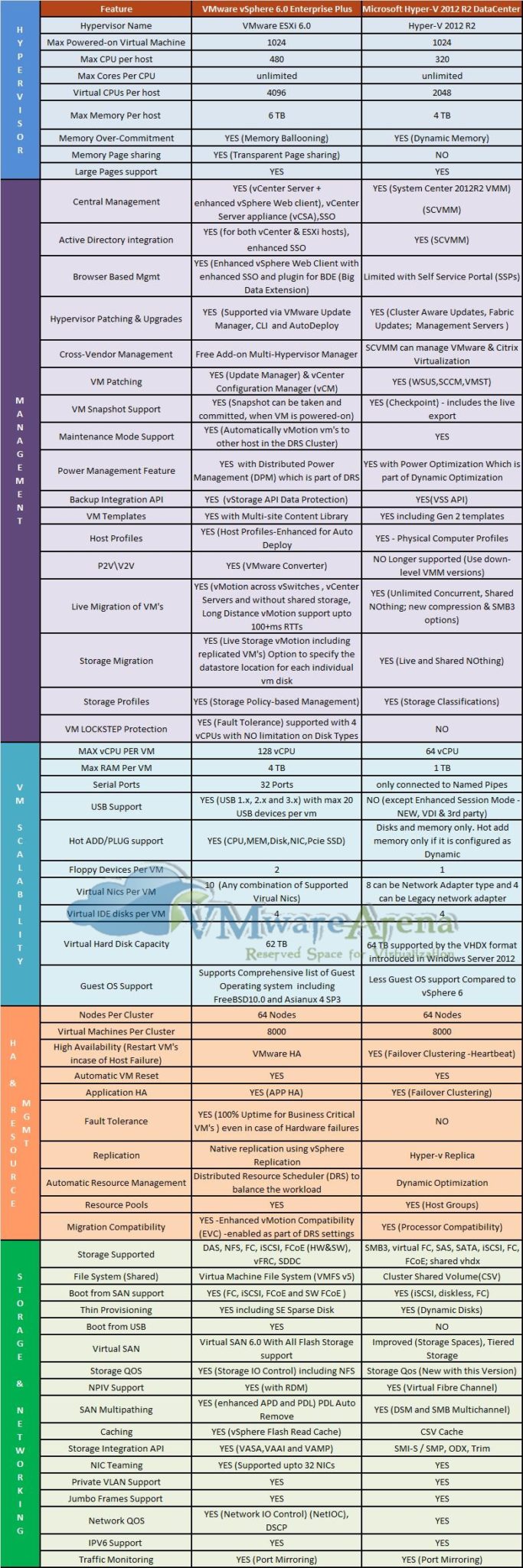
Не так давно на сайте VMwareArena появилось очередное сравнение VMware vSphere (в издании Enterprise Plus) и Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition, которое включает в себя самую актуальную информацию о возможностях обеих платформ.
Мы адаптировали это сравнение в виде таблицы и представляем вашему вниманию ниже:
Группа возможностей
Возможность
VMware vSphere 6
Enterprise Plus
Microsoft Hyper-V в Windows Server 2012 R2 Datacenter Edition
Возможности гипервизора
Версия гипервизора
VMware ESXi 6.0
Hyper-V 2012 R2
Максимальное число запущенных виртуальных машин
1024
1024
Максимальное число процессоров (CPU) на хост-сервер
480
320
Число ядер на процессор хоста
Не ограничено
Не ограничено
Максимальное число виртуальных процессоров (vCPU) на хост-сервер
4096
2048
Максимальный объем памяти (RAM) на хост-сервер
6 ТБ
4 ТБ
Техники Memory overcommitment (динамическое перераспределение памяти между машинами)
Memory ballooning
Dynamic Memory
Техники дедупликации страниц памяти
Transparent page sharing
Нет
Поддержка больших страниц памяти (Large Memory Pages)
Да
Да
Управление платформой
Централизованное управление
vCenter Server + vSphere Client + vSphere Web Client, а также виртуальный модуль vCenter Server Appliance (vCSA)
System Center Virtual Machine Manager (SC VMM)
Интеграция с Active Directory
Да, как для vCenter, так и для ESXi-хостов через расширенный механизм SSO
Да (через SC VMM)
Поддержка снапшотов (VM Snapshot)
Да, снапшоты могут быть сделаны и удалены для работающих виртуальных машин
Да, технология Checkpoint, включая функции live export
Управление через браузер (тонкий клиент)
Да, полнофункциональный vSphere Web Client
Ограниченное, через Self Service Portal
Обновления хост-серверов / гипервизора
Да, через VMware Update Manager (VUM), Auto Deploy и CLI
Да - Cluster Aware Updates, Fabric Updates, Management Servers
Управление сторонними гипервизорами
Да, бесплатный аддон Multi-Hypervisor Manager
Да, управление VMware vCenter и Citrix XenCenter поддерживается в SC VMM
Обновление (патчинг) виртуальных машин
Да, через VMware Update Manager (VUM) и vCenter Configuration Manager (vCM)
Да (WSUS, SCCM, VMST)
Режим обслуживания (Maintenance Mode)
Да, горячая миграция ВМ в кластере DRS на другие хосты
Да
Динамическое управление питанием
Да, функции Distributed Power Management в составе DRS
Да, функции Power Optimization в составе Dynamic Optimization
API для решений резервного копирования
Да, vStorage API for Data Protection
Да, VSS API
Шаблоны виртуальных машин (VM Templates)
Да + Multi-site content library
Да, включая шаблоны Gen2
Профили настройки хостов (Host Profiles)
Да, расширенные функции host profiles и интеграция с Auto Deploy
Да, функции Physical Computer Profiles
Решение по миграции физических серверов в виртуальные машины
Да, VMware vCenter Converter
Нет, больше не поддерживается
Горячая миграция виртуальных машин
Да, vMotion между хостами, между датацентрами с разными vCenter, Long Distance vMotion (100 ms RTT), возможна без общего хранилища
Да, возможна без общего хранилища (Shared Nothing), поддержка компрессии и SMB3, неограниченное число одновременных миграций
Горячая миграция хранилищ ВМ
Да, Storage vMotion, возможность указать размещение отдельных виртуальных дисков машины
Да
Профили хранилищ
Да, Storage policy-based management
Да, Storage Classifications
Кластер непрерывной доступности ВМ
Да, Fault Tolerance с поддержкой до 4 процессоров ВМ, поддержка различных типов дисков, технология vLockstep
Нет
Конфигурации виртуальных машин
Виртуальных процессоров на ВМ
128 vCPU
64 vCPU
Память на одну ВМ
4 ТБ
1 ТБ
Последовательных портов (serial ports)
32
Только присоединение к named pipes
Поддержка USB
До 20 на одну машину (версии 1,2 и 3)
Нет (за исключением Enhanced Session Mode)
Горячее добавление устройств
(CPU/Memory/Disk/NIC/PCIe SSD)
Только диск и память (память только, если настроена функция Dynamic memory)
Диски, растущие по мере наполнения данными (thin provisioning)
Да (thin disk и se sparse)
Да, Dynamic disks
Поддержка Boot from USB
Да
Нет
Хранилища на базе локальных дисков серверов
VMware Virtual SAN 6.0 с поддержкой конфигураций All Flash
Storage Spaces, Tiered Storage
Уровни обслуживания для подсистемы ввода-вывода
Да, Storage IO Control (работает и для NFS)
Да, Storage QoS
Поддержка NPIV
Да (для RDM-устройств)
Да (Virtual Fibre Channel)
Поддержка доступа по нескольким путям (multipathing)
Да, включая расширенную поддержку статусов APD и PDL
Да (DSM и SMB Multichannel)
Техники кэширования
Да, vSphere Flash Read Cache
Да, CSV Cache
API для интеграции с хранилищами
Да, широкий спектр VASA+VAAI+VAMP
Да, SMI-S / SMP, ODX, Trim
Поддержка NIC Teaming
Да, до 32 адаптеров
Да
Поддержка Private VLAN
Да
Да
Поддержка Jumbo Frames
Да
Да
Поддержка Network QoS
Да, NetIOC (Network IO Control), DSCP
Да
Поддержка IPv6
Да
Да
Мониторинг трафика
Да, Port mirroring
Да, Port mirroring
Подводя итог, скажем, что нужно смотреть не только на состав функций той или иной платформы виртуализации, но и необходимо изучить, как именно эти функции реализованы, так как не всегда реализация какой-то возможности позволит вам использовать ее в производственной среде ввиду различных ограничений. Кроме того, обязательно нужно смотреть, какие функции предоставляются другими продуктами от данного вендора, и способны ли они дополнить отсутствующие возможности (а также сколько это стоит). В общем, как всегда - дьявол в деталях.
Таги: VMware, vSphere, Hyper-V, Microsoft, Сравнение, ESXi, Windows, Server
Как вы знаете, в новой версии решения VMware Horizon 6.2 для виртуализации настольных ПК компания VMware сделала специальное издание VMware Horizon for Linux, позволяющее создавать инфраструктуру виртуальных десктопов на базе компьютеров с хостовой ОС Linux. Это востребовано в организациях, где такие рабочие станции используются для графического моделирования, сложных расчетов и прочих требовательных к производительности графической подсистемы нагрузок.
Напомним, что еще с версии Horizon 6.2 полностью поддерживались режимы Virtual Shared Graphics Acceleration (vSGA), Virtual Dedicated Graphics Acceleration (vDGA) и NVIDIA GRID vGPU на базе GRID 2.0 для Linux-десктопов:
Дистрибутив Linux
Режимы работы 3D-графики
vSGA
vDGA
vGPU
Red Hat Enterprise Linux 6.6 Workstation x86_64
Нет
Horizon 6.1.1 или более поздний
Требует адаптера NVIDIA M60, GRID 2.0, а также Horizon 6.2 или более поздний
Red Hat Enterprise Linux 7.1 Workstation x86_64
Horizon 6.2 или более поздний
Нет
Требует адаптера NVIDIA M60, GRID 2.0, а также Horizon 6.2 или более поздний
Совсем недавно компания VMware выпустила VMware Horizon 6.2.1, где в плане поддержки Linux-десктопов появилось еще несколько нужных новых возможностей:
1. Clipboard Redirection (Copy / Paste).
Теперь в Linux-десктопах появилось перенаправление клавиатуры, которое позволяет копировать и вставлять из хостового ПК в виртуальный и обратно текст с форматированием, а также картинки. Естественно, в целях безопасности можно эту функцию отключить в файле конфигурации /etc/vmware/config (см. документ "Setting Up Horizon 6 for Linux Desktops").
2. Single Sign-On.
Теперь в Linux-ПК появилась поддержка SSO, позволяющая пользователю хостового устройства не вводить учетные данные при логине в свой виртуальный ПК Linux, который интегрирован со службами Active Directory через Open LDAP. Эти возможности поддерживаются для Horizon Client под Mac, Windows и Linux. На данный момент функция доступна только для ПК Red Hat Enterprise Linux 6.6 Workstation x86_64 и CentOS 6.6 x86_64.
3. Smart Card Authentication.
Аутентификация через смарт-карты в виртуальном ПК требуется во многих государственных и частных организациях с соответствующими регулирующими процедурами. Для аутентификации поддерживаются карты типа Personal Identity Verification (PIV) и Common Access Cards (CAC) с дистрибутивом Red Hat Enterprise Linux 6.6 Workstation x86_64.
4. Kerberos Authentication
После установки View Agent в виртуальный ПК Linux вы можете выбрать тип аутентификации Kerberos в дополнение к уже имеющейся MD5 digest authentication.
5. Consolidated Client Environment Information
До VMware Horizon 6.2.1 вся информация о пользовательском окружении (имя хоста, IP-адрес и прочее) записывалась в стандартный лог-файл, содержащий отладочную информацию. Это было неудобно, так как файл большой, и выуживать из него нужные данные было тяжело. Теперь для этого есть отдельный файл /var/log/vmware/Environment.txt, который поможет решать проблемы при настройке инфраструктуры виртуальных ПК.
Получить VMware Horizon 6.2.1 for Linux можно двумя способами:
1. Купить лицензию VMware Horizon 6 Enterprise Edition, которая содержит все необходимое для построения VDI-инфраструктуры, в том числе на Linux-платформе.
2. Использовать специализированное издание Horizon 6 for Linux standalone, которое можно скачать по этой ссылке.
Иногда системному администратору VMware vSphere требуется узнать, сколько тот или иной хост ESXi работает с момента последней загрузки (например, требуется проверить, не было ли внеплановых ребутов).
Есть аж целых 5 способов сделать это, каждый из них можно применять в зависимости от ситуации.
1. Самый простой - команда uptime.
Просто заходим на хост ESXi из консоли или по SSH и выполняем команду uptime:
login as: root
Using keyboard-interactive authentication.
Password: XXXXXX
The time and date of this login have been sent to the system logs.
VMware offers supported, powerful system administration tools. Please
see www.vmware.com/go/sysadmintools for details.
The ESXi Shell can be disabled by an administrative user. See the
vSphere Security documentation for more information.
~ # uptime
04:26:24 up 00:20:42, load average: 0.01, 0.01, 0.01
2. С помощью команды esxtop.
С помощью утилиты esxtop можно не только отслеживать производительность хоста в различных аспектах, но и узнать его аптайм. Обратите внимание на самую первую строчку вывода:
# esxtop
4. Время запуска хоста из лога vmksummary.log.
Вы можете посмотреть не только время текущего аптайма хоста ESXi, но времена его прошлых запусков в логе vmksummary.log. Для этого выполните следующую команду:
cat /var/log/vmksummary.log |grep booted
2015-06-26T06:25:27Z bootstop: Host has booted
2015-06-26T06:47:23Z bootstop: Host has booted
2015-06-26T06:58:19Z bootstop: Host has booted
2015-06-26T07:05:26Z bootstop: Host has booted
2015-06-26T07:09:50Z bootstop: Host has booted
2015-07-08T05:32:17Z bootstop: Host has booted
4. Аптайм в vSphere Client и Web Client.
Если вы хотите вывести аптайм сразу всех виртуальных машин на хосте в VMware vSphere Client, для этого есть специальная колонка в представлении Hosts:
5. Аптайм хостов через PowerCLI.
Конечно же, время работы хоста ESXi можно посмотреть и через интерфейс PowerCLI. Для этого нужно воспользоваться командлетом Get-VMHost:
В новой книге Фрэнка на 300 страницах раскрываются следующие моменты, касающиеся производительности подсистемы хранения платформ виртуализации, построенной на базе локальных дисков хост-серверов:
Новая парадигма построения виртуального датацентра с точки зрения систем хранения
Архитектура решения FVP
Ускорение доступа к данным
Технология непрерывной доступности Fault Tolerance
Технология Flash
Техники доступа к памяти
Настройка кластера решения FVP
Сетевой дизайн инфраструктуры локальных хранилищ
Внедрение и пробная версия решения FVP
Дизайн инфраструктуры хранилищ
Несмотря на то, что книга рассматривает в качестве основного продукта решение FVP от компании PernixData, ее интересно читать и с точки зрения понимания архитектуры и производительности подобных решений.
Если вы посмотрите в документ VSAN Troubleshooting Reference Manual (кстати, очень нужный и полезный), описывающий решение проблем в отказоустойчивом кластере VMware Virtual SAN, то обнаружите там такую расширенную настройку, как VSAN.ClomMaxComponentSizeGB.
Когда кластер VSAN хранит объекты с данными виртуальных дисков машин, он разбивает их на кусочки, растущие по мере наполнения (тонкие диски) до размера, указанного в данном параметре. По умолчанию он равен 255 ГБ, и это значит, что если у вас физические диски дают полезную емкость меньше данного объема (а точнее самый маленький из дисков в группе), то при достижении тонким диском объекта предела физической емкости вы получите вот такое сообщение:
There is no more space for virtual disk XX. You might be able to continue this session by freeing disk space on the relevant volume and clicking retry.
Если, например, у вас физический диск на 200 ГБ, а параметры FTT и SW равны единице, то максимально объект виртуального диска машины вырастет до этого размера и выдаст ошибку. В этом случае имеет смысл выставить настройку VSAN.ClomMaxComponentSizeGB на уровне не более 80% емкости физического диска (то есть, в рассмотренном случае 160 ГБ). Настройку эту нужно будет применить на каждом из хостов кластера Virtual SAN.
Как это сделать (более подробно об этом - в KB 2080503):
В vSphere Web Client идем на вкладку Manage и кликаем на Settings.
Под категорией System нажимаем Advanced System Settings.
Выбираем элемент VSAN.ClomMaxComponentSizeGB и нажимаем иконку Edit.
Устанавливаем нужное значение.
Надо отметить, что изменение этой настройки работает только для кластера VSAN без развернутых на нем виртуальных машин. Если же у вас уже продакшен-инфраструктура столкнулась с такими трудностями, то вы можете воспользоваться следующими двумя способами для обхода описанной проблемы:
1. Задать Object Space Reservation в политике хранения (VM Storage Policy) таким образом, чтобы дисковое пространство под объекты резервировалось сразу (на уровне 100%). И тогда VMDK-диски будут аллоцироваться целиком и распределяться по физическим носителям по мере необходимости.
2. Задать параметр Stripe Width в политиках VM Storage Policy таким образом, чтобы объекты VMDK распределялись сразу по нескольким физическим накопителям.
Фишка еще в том, что параметрVSAN.ClomMaxComponentSizeGB не может быть выставлен в значение, меньшее чем 180 ГБ, а значит если у вас носители меньшего размера (например, All-Flash конфигурация с дисками меньше чем 200 ГБ) - придется воспользоваться одним из этих двух способов, чтобы избежать описанной ошибки. Для флеш-дисков 200 ГБ установка значения в 180 ГБ будет ок, несмотря на то, что это уже 90% физической емкости.
Имя компьютера/сервера не всегда является достаточно информативным, например, имя «DC01» скажет вам намного меньше, чем «DC: Сайт Москва - GC, FSMO: Schema, RID, PDC». Поскольку имя компьютера NetBIOS/Hostname имеет ограничения как по длине, так и по набору символов, то для хранения этой дополнительной информации и предназначено поле «Description». Оно существует как для компьютера, т.е. внутри ОС (System Properties)...
«За выдающийся вклад технического партнера в продвижение серверных систем NetApp» — такую награду получила компания ИТ-ГРАД, предоставляющая услуги хостинга виртуальных машин, на специальном мероприятии NetApp Insight 2015 в Германии. Комментарий от компании ИТ-ГРАД:
Для нас это несколько больше, чем просто еще одна красивая стеклянная фигурка. Как известно многим нашим заказчикам, ИТ-ГРАД не только предоставляет услуги по облачному хостингу в модели IaaS, но и поставляет системы хранения данных, серверное и сетевое оборудование. Вне зависимости от того, собираетесь ли вы модернизировать свою ИТ-инфраструктуру или разработать собственное облако (почему бы и нет?) – у нас вы всегда сможете получить грамотную консультацию и заказать необходимое оборудование.
В качестве СХД мы сами используем хранилища NetApp FAS и рекомендуем их заказчикам с такими же высокими требованиями к надежности и производительности. ИТ-ГРАД не просто продает серверное оборудование, но и осуществляет техническую поддержку по самым разным техническим вопросам. Многолетний собственный опыт и регулярное повышение квалификации инженеров – это наш залог успешного внедрения и эксплуатации корпоративных систем.
За последние годы наше предложение по хранилищам NetApp перешло из разряда дополнительной деятельности в активно развивающееся направление, с хорошим ростом продаж. Настолько хорошим, что статистику оценил сам вендор и включил нас в список лучших российских поставщиков систем хранения NetApp.
Те из вас, кто использовал решение для обеспечения высокой доступности хранилищ под виртуализацию StarWind Virtual SAN, знают, что в продукте предусмотрена возможность асинхронной репликации данных на резервный узел для обеспечения катастрофоустойчивости. В этом случае на резервную площадку откидывается снапшот данных основного узла по заданному администратором расписанию.
В документе приведены как общие сведения об устройстве механизма асинхронной репликации данных StarWind Virtual SAN, так и подробные пошаговые инструкции по его настройке. Также советуем посмотреть еще один документ StarWind об асинхронной репликации.
Как вы знаете, некоторое время назад вышло обновление платформы виртуализации VMware vSphere 6 Update 1, в котором были, в основном, только минорные обновления. Но было и важное - теперь виртуальный модуль VMware vCenter Server Appliance (vCSA) стало возможно обновлять путем монтирования к нему ISO-образа с апдейтом.
Давайте покажем упрощенный процесс обновления через смонтированный образ. Итак, соединимся с хостом vCSA по SSH (если у вас есть отдельный сервер Platform Services Controller, то коннектиться нужно к нему):
Далее скачаем обновление vCenter, в котором есть и обновление vCSA версии 6.0.0 (выберите продукт VC и в разделе VC-6.0.0U1-Appliance скачайтеVMware-vCenter-Server-Appliance-6.0.0.10000-3018521-patch-FP.iso):
Здесь надо пояснить, что это за обновления:
FP (Full patch) - это обновление всех компонентов vCenter, включая полноценные продукты, vCenter, vCSA, VMware Update Manager, PSC и прочее.
TP (Third party patch) - это обновление только отдельных компонентов vCenter.
Скачиваем патч FP (VMware-vCenter-Server-Appliance-6.0.0.10000-3018521-patch-FP.iso), после чего монтируем этот ISO-образ к виртуальной машине vCSA через vSphere Web Client или Embedded Host Client.
Далее возвращаемся к консоли vCSA:
Смонтировать ISO-образ можно также через PowerCLI с помощью следующих команд:
Далее выполняем следующую команду, если вы хотите накатить патчи прямо сейчас:
software-packages install --iso --acceptEulas
Либо патчи можно отправить на стейджинг отстаиваться (то есть пока обновить компоненты, но не устанавливать). Сначала выполняем команду отсылки на стейджинг:
software-packages install --iso --acceptEulas
Далее просматриваем содержимое пакетов:
software-packages list --staged
И устанавливаем апдейт со стейджинга:
software-packages install --staged
Если во время обновления на стейджинг или установки обновления возникли проблемы, вы можете просмотреть логи, выполнив следующие команды:
shell.set –enabled True shell cd /var/log/vmware/applmgmt/ tail software-packaged.log –n 25
Далее размонтируйте ISO-образ от виртуальной машины или сделайте это через PowerCLI следующей командой:
shutdown reboot -r "Updated to vCenter Server 6.0 Update 1"
Теперь откройте веб-консоль vCSA по адресу:
https://<FQDN-or-IP>:5480
И перейдите в раздел Update, где вы можете увидеть актуальную версию продукта:
Кстати, обратите внимание, что возможность проверки обновления в репозитории (Check URL) вернулась, и обновлять vCSA можно прямо отсюда по кнопке "Check Updates".
Многие из вас знают, что в решении VMware Horizon View есть две полезных возможности, касающихся функций печати из виртуального ПК пользователя - это перенаправление принтеров (Printer redirection) и печать на основе местоположения (Location based printing). Об этих функциях подробно рассказано в документе "Virtual Printing Solutions with View in Horizon 6", а мы изложим тут лишь основные сведения, содержащиеся в нем.
Printer redirection
Эта возможность позволяет перенаправить печать из виртуального ПК к локальному устройству пользователя, с которого он работает, и к которому подключен принтер уже физически. Функция поддерживается не только для Windows-машин, но и для ПК с ОС Linux и Mac OS X. Работает эта фича как для обычных компьютеров, так и для тонких клиентов (поддерживается большинство современных принтеров).
При печати пользователь видит принтер хоста не только в диалоге печати приложения, но и в панели управления. При этом не требуется в виртуальном ПК иметь драйвер принтера - достаточно, чтобы он был установлен на хостовом устройстве.
Перенаправление принтеров полезно в следующих случаях:
в общем случае, когда к физическому ПК пользователя привязан принтер
когда пользователь работает из дома со своим десктопом и хочет что-то распечатать на домашнем принтере
работники филиала печатают на локальных принтерах, в то время, как сами десктопы расположены в датацентре центрального офиса
Схема передачи задания на печать для перенаправления принтера выглядит так:
То есть Horizon Client получает данные в формате EMF от виртуального ПК и передает его уже на хостовом устройстве к драйверу принтера.
Location based printing
Эта фича позволяет пользователям виртуальных ПК печатать на тех принтерах, которые находятся географически ближе к нему, чтобы не бегать, например, на другой этаж офисного здания, чтобы забирать распечатанное, когда есть принтеры поблизости. Правила такой печати определяются системным администратором.
Для функции Location based printing задания печати направляются с виртуального ПК напрямую на принтер, а значит нужно, чтобы на виртуальном десктопе был установлен драйвер этого принтера.
Есть 2 типа правил Location based printing:
IP-based printing - используется IP-адрес принтера для определения правил маппинга принтера к десктопам.
UNC-based printing - используются пути в формате Universal Naming Convention (UNC) для определения правил маппинга принтеров.
Здесь задание на печать передается в рамках следующего рабочего процесса:
Запрос пользователя с хостового устройства через Horizon Client передается к View Agent, который через взаимодействие с приложением передает задание драйверу принтера в гостевой ОС с учетом правил маппинга принтеров, а дальше уже обработанное задание идет на печать.
В зависимости от способа доступа, поддерживаются методы перенаправления принтеров или печать на основе местоположения:
Очевидно, что в нулевом клиенте и в мобильном девайсе нет хостового драйвера принтера, поэтому там и нет поддержки Printer redirection. Ну и то же самое можно сказать про доступ HTML access через браузер - там тоже поддержка отсутствует.
Надо сказать, что и Printer redirection, и Location based printing поддерживаются для следующих моделей доступа пользователей инфраструктуры VDI:
Десктопы View
Десктопы RDSH
Десктопы Windows Server 2008 R2 и Windows Server 2012 R2
Приложения Hosted apps
Ну а о том, как настраивать обе техники печати из виртуальных ПК вы можете прочитать в документе.
Представляем гостевой пост компании 1cloud, предоставляющей услуги в области хостинга виртуальных машин по модели IaaS. С падением цен на SSD все больше компаний предлагают массивы, целиком построенные на флеш-памяти, но действительно ли они лучше гибридных массивов, содержащих как твердотельные накопители, так и жесткие диски?
Мы уже писали о том, что последней версии решения для виртуализации настольных ПК VMware Horizon View 6.2 есть поддержка режима vGPU. Напомним, что это самая прогрессивная технология NVIDIA для поддержки требовательных к производительности графической подсистемы виртуальных десктопов.
Ранее мы уже писали про режимы Soft 3D, vSGA и vDGA, которые можно применять для виртуальных машин, использующих ресурсы графического адаптера на стороне сервера.
Напомним их:
Soft 3D - рендеринг 3D-картинки без использования адаптера на основе программных техник с использованием памяти сервера.
vDGA - выделение отдельного графического адаптера (GPU) одной виртуальной машине.
vSGA - использование общего графического адаптера несколькими виртуальными машинами.
Режим vSGA выглядит вот так:
Здесь графическая карта представляется виртуальной машине как программный видеодрайвер, а графический ввод-вывод обрабатывается через специальный драйвер в гипервизоре - ESXi driver (VIB-пакет). Команды обрабатываются по принципу "first come - first serve".
Режим vDGA выглядит вот так:
Здесь уже физический GPU назначается виртуальной машине через механизм проброса устройств DirectPath I/O. То есть целый графический адаптер потребляется виртуальной машиной, что совсем неэкономно, но очень производительно.
В этом случае специальный драйвер NVIDIA GPU Driver Package устанавливается внутри виртуальной машины, а сам режим полностью поддерживается в релизах Horizon View 5.3.х и 6.х (то есть это давно уже не превью и не экспериментальная технология). Этот режим работает в графических картах K1 и K2, а также и более свежих адаптерах, о которых речь пойдет ниже.
Режим vGPU выглядит вот так:
То есть встроенный в гипервизор NVIDIA vGPU Manager (это тоже драйвер в виде пакета ESXi VIB) осуществляет управление виртуальными графическими адаптерами vGPU, которые прикрепляются к виртуальным машинам в режиме 1:1. В операционной системе виртуальных ПК также устанавливается GRID Software Driver.
Здесь уже вводится понятие профиля vGPU (Certified NVIDIA vGPU Profiles), который определяет типовую рабочую нагрузку и технические параметры десктопа (максимальное разрешение, объем видеопамяти, число пользователей на физический GPU и т.п.).
vGPU можно применять с первой версией технологии GRID 1.0, которая поддерживается для графических карт K1 и K2:
Но если мы говорим о последней версии технологии GRID 2.0, работающей с адаптерами Tesla M60/M6, то там все устроено несколько иначе. Напомним, что адаптеры Tesla M60 предназначены для Rack/Tower серверов с шиной PCIe, а M6 - для блейд-систем различных вендоров.
Технология NVIDIA GRID 2.0 доступна в трех версиях, которые позволяют распределять ресурсы между пользователями:
Характеристики данных лицензируемых для адаптеров Tesla изданий представлены ниже:
Тут мы видим, что дело уже не только в аппаратных свойствах графической карточки, но и в лицензируемых фичах для соответствующего варианта использования рабочей нагрузки.
Каждый "experience" лицензируется на определенное число пользователей (одновременные подключения) для определенного уровня виртуальных профилей. Поэтому в инфраструктуре GRID 2.0 добавляется еще два вспомогательных компонента: Licensing Manager и GPU Mode Change Utility (она нужна, чтобы перевести адаптер Tesla M60/M6 из режима compute mode в режим graphics mode для работы с соответствующим типом лицензии виртуальных профилей).
Обратите внимание, что поддержка гостевых ОС Linux заявлена только в последних двух типах лицензий.
На данный момент сертификацию драйверов GRID прошло следующее программное обеспечение сторонних вендоров (подробнее об этом тут):
Спецификации карточек Tesla выглядят на сегодняшний день вот так:
Поддержка также разделена на 2 уровня (также прикрепляется к лицензии):
Руководство по развертыванию NVIDIA GRID можно скачать по этой ссылке, ну а в целом про технологию написано тут.
Мероприятие пройдет 15 декабря в 11:00 по московскому времени. Вебинар проведет Денис Полянский, менеджер по продукту компании «Код Безопасности». Таги:
Когда вы выбираете облачного провайдера под проект IaaS, основное внимание уделяется характеристикам самого облака. Вы уточняете время доступности сервисов, гарантированные параметры производительности, возможности расширения набора облачных ресурсов и т. п. Но за любым виртуальным облаком кроется реальное оборудование, установленное в четырех стенах на некой территории. И от надежности всей этой «фоновой» инфраструктуры в значительной степени зависит надежность нового разворачиваемого в облаке сервиса.
Так как облачные вычисления привлекают не только маленькие компании с невысокой зависимостью от ИТ, но и действительно крупные корпорации с полностью «цифровыми» бизнес-направлениями, ко всем компонентам стоит отнестись особенно внимательно. Дело в том, что облачный провайдер часто оперирует характеристиками собственных сервисов, декларируя тот или иной уровень надежности (привычные нам «девятки»). Но даже если предположить, что в цифрах заявленной надежности и производительности нет лукавства, остается открытым вопрос соответствия подобным показателям нижележащей инфраструктуры. Ведь никакое дублирование и кластеризация не помогут вашим облачным виртуальным машинам при перегреве оборудования в машинном зале.
Не стоит забывать и о национальных особенностях ИТ-бизнеса. Далеко не все коммерческие дата-центры имеют официальную сертификацию по классу надежности, и еще меньшее их число подтверждено реальным независимым аудитом. Увы, но все еще встречаются разнообразные «внутренние сертификации», «нам это не нужно, мы уверены» и «заявленный уровень надежности — TIER III+» (с этими плюсами ситуация вообще забавная, но об этом позже).
Чтобы избежать будущих и вполне реальных неприятностей на ровном месте, рекомендуем внимательно подойти к выбору облачного поставщика, самостоятельно проверив характеристики его дата-центров. В конце концов, вы имеете полное право знать, где и как хранится ваша информация и насколько надежен «цифровой фундамент» бизнеса. Далее мы будем говорить преимущественно о самих ЦОД, отложив в сторону особенности облачных провайдеров.
Чем отличается надежность со стороны клиента и владельца дата-центра
Очевидно, что у владельца ЦОД и его клиента совершенно разные цели и ориентиры. Если вы, как будущий заказчик, стремитесь получить максимально качественный и отвечающий требованиям продукт за разумные деньги, то провайдер, скорее всего, пойдет по пути наименьшего сопротивления. И быть бы всем нашим ЦОД максимально примитивными, если бы не требования рынка. Многие заказчики откажутся пользоваться услугами ЦОД без резервных источников питания и дублированной системы охлаждения. А некоторые еще и обратят внимание на географическое расположение и характеристики самого здания с машинным залом.
В то же время можно встретить немало ЦОД, где систему охлаждения проектировали несведущие в вопросе люди, оба «независимых» подвода питания исходят из одной магистральной линии города либо для дизельного генератора не предусмотрено своевременного подвоза топлива. Да что там говорить, мне лично доводилось видеть дата-центр, где холодный коридор был реализован двумя кондиционерами, дующими в некую точку посередине. Очевидно, что температура оборудования в крайних стойках может и не уложиться в ожидаемые пределы при высокой нагрузке.
Что же обычно хочет видеть заказчик при оценке надежности дата-центра:
Непрерывную работу ЦОД не менее определенного значения в год. На этот фактор влияет уровень резервирования всех ключевых узлов (охлаждение, электропитание, класс серверного оборудования).
Соразмерный ожиданиям заказчика уровень гарантированной производительности.
Возможности по защите информации от хищения. Сюда входит скорее риск физического доступа к оборудованию посторонних лиц, то есть речь идет об охране.
Между тем порой упускаются важные и неочевидные моменты, которые могут вылиться в серьезные неприятности:
Юридический статус ЦОД (права собственности, разрешения всех государственных инстанций и прочее).
Наличие всех необходимых контрактов на обслуживание систем и их поддержку при наступлении аварийной ситуации (тот же контракт на подвозку дизельного топлива для генераторов или план проверок всех систем на готовность к отработке аварии).
Возможности работы инженерных систем при нетипичных температурах и погодных аномалиях.
Проектирование инфраструктуры в соответствии с принятыми в отрасли нормами и правилами.
Разумеется, список неполный. Но даже этот перечень заставляет задуматься о существовании множества особенностей и нюансов, которые при проектировании объекта балансируют между стоимостью и возможностями. Дабы упорядочить ситуацию и внести какое-то подобие структуры, в 1993 году в США был основан The Uptime Institute (UTI), который является лидером в области оценки надежности и доступности дата-центров. Uptime Institute признан мировым ИТ-сообществом как независимый аудитор соответствия ЦОД требованиям отказоустойчивости.
UTI
Организация Uptime Institute за время своего существования собрала информацию о тысячах происшествий в дата-центрах по всему миру. Эти данные использовались для создания классификации по уровням готовности Tier Classification. Этот классификатор через некоторое время стал стандартом де-факто и был включен в состав американского стандарта построения центров обработки данных TIA/EIA-942.
Классификатор состоит из четырех уровней (Tier1 — 4), где большее число означает более высокий уровень надежности:
Tier 1 предполагает отсутствие резервирования систем электропитания и охлаждения машинного зала, отсутствие резервирования серверных систем. Фактически инженерная инфраструктура просто должна быть собственной и иметь подстраховку на случай перебоев с электропитанием (генератор). Уровень доступности — 99,671 %, что соответствует примерно 28,8 часам простоев ежегодно.
Tier 2 основывается на Tier 1, но предполагает резервирование всех активных систем. Это уже более надежный класс, который все же допускает около 22 часов простоев в год (99,75 %).
Tier 3 уже может считаться работающим без остановок. На этом уровне обязательно должны быть зарезервированы все инженерные системы (включая пассивные), должны обеспечиваться возможности ремонта и модернизации без остановки сервисов. Tier 3 фактически предполагает постройку второго ЦОД внутри того же здания — дублирующая СКС, подводы электричества, отдельная система охлаждения, у всего серверного оборудования независимые подключения к нескольким источникам питания. Допускается не более 1,6 часа простоев в год (99,98 %);
Tier 4 является дальнейшим развитием третьего уровня и, помимо резервирования всех систем, предполагает сохранение уровня отказоустойчивости даже при аварии. Схема позволяет гарантировать непрерывность работы при любых умышленных или случайных поломках, допуская простой продолжительностью лишь 0,8 часа ежегодно (99,99 %).
Для вашего удобства я собрал отличия уровней надежности в табличку:
Приходите на вебинар, чтобы узнать, как именно можно получить максимальный эффект от использования All-Flash хранилищ серверов хранения в сочетании с виртуализацией и проприетарной высокопроизводительной файловой системой LSFS от компании StarWind. Ребята действительно очень далеко продвинулись в этом плане.
Как вы знаете, у компании VMware есть средство для комплексного мониторинга и решения проблем в виртуальной среде vRealize Operations. Также в решении для создания инфраструктуры виртуальных ПК предприятия VMware Horizon View (еще с версии 6.0) есть поддержка опубликованных приложений на серверах RDS Hosted Apps.
Ну и логично, что у VMware есть решение vRealize Operations for Published Applications, которое поддерживает мониторинг инфраструктуры доставки приложений через механизм RDS Hosted Apps. На днях вышла обновленная версия этого продукта - vRealize Operations for Published Applications 6.2 одновременно с основным релизом Operations 6.2, с поддержкой не только приложений опубликованных, через RDS, но и продуктов Citrix XenApp и XenDesktop.
Основные новые возможности vRealize Operations for Published Applications 6.2:
Поддержка последних версий Citrix XenDesktop and XenApp 7.6 - функции мониторинга и отчетности теперь доступны для инфраструктуры виртуализации и доставки приложений и десктопов, созданных на данных платформах.
Application and Usage Reports - готовые шаблоны отчетов, которые позволяют администраторам приложений определить потребление ресурсов приложениями, пиковые нагрузки, параметры сессий пользователей на серверных ресурсах, а также учитывать потребление пользователями лицензий отдельных приложений.
Proactive User Experience Monitoring - новый дэшборд "User Experience", который постоянно мониторит vCPU, vRAM и vDisk, чтобы с помощью карты heat map оповестить администратора о том, что некоторые пользователи испытывают проблемы при работе с их приложениями.
Reduced Time to Resolve - новые метрики сессии, которые помогают устранять проблемы: длительность процесса логина, сортировка по времени логина сессий, использование системных ресурсов, а также ICA Round Trip Time для приложений Citrix.
Windows 10 support - теперь Windows 10 поддерживается для мониторинга, как для VMware Horizon View, так и для решений XenDesktop/XenApp.
Алерты для Citrix Storefront, PVS Server, Citrix License Server и Citrix Database Server - теперь все эти компоненты поддерживаются в рамках общей процедуры мониторинга доступности компонентов инфраструктры виртуальных ПК и приложений.
Мониторинг лицензий Citrix License Server - теперь можно учитывать лицензии, считаемые этим продуктом.
Improved Logon Breakdown metrics to meet SLAs - дэшборд "Session Details" теперь показывает метрику длительность процесса логина для самых тормозных ПК.
Connection and machine failure data - эта новая метрика мониторит общее число неудачных соединений и стартов машин на ферме Citrix XenDesktop.
Более подробно о новых функциях решения vRealize Operations for Published Applications 6.2 написано в Release Notes. Напомним, что это решение включено в состав продукта vRealize Operations for Horizon, который можно скачать по этой ссылке.
Microsoft находится накануне релиза одного из своих самых крупных технологических достижений со времен Windows NT - Nano Server. Их рывок в ряды ведущих поставщиков услуг с Azure и Office 365 усилил некоторые ключевые потребности в технологиях для ЦОД. На ум приходит сленговое выражение: "Есть свой собственный корм". Это означает, что Microsoft теперь использует свое же собственное программное обеспечение в больших объемах, как клиент. В статье мы расскажем об управлении Nano Server средствами 5nine.
Таги: 5nine, Manager, Hyper-V, Update, Nano Server, Microsoft
Компания VMware на днях выпустила обновление своей платформы виртуализации для Mac OS - VMware Fusion 8.1. Напомним, что о прошлой версии VMware Fusion 8 мы писали вот тут.
Интересно, что эта версия продукта не предоставляет новых возможностей, но несет в себе достаточно много исправлений ошибок, что означает, что их в восьмой версии было немало (вообще говоря, в последнее время VMware довольно часто выпускает продукты с серьезными багами).
От себя скажу, что для меня лично была очень актуальна ошибка с задержками при работе в Excel - пишут что был "one-second delay", однако ничего подобного - у меня вся машина фризилась секунд на 20-30, пока я не обновил Fusion.
Итак, какие багофиксы были сделаны:
Исправления ошибок для упрощенного процесса инсталляции гостевых ОС из ISO-образов Windows 10 и Windows server 2012 R2.
Исправлена ошибка с неработающим обратным DNS lookup в виртуальной машине, когла на Mac-хосте установлен сервер dnsmasq.
Исправление ошибки с крэшем машины при отключении внешнего монитора от Mac, когда Fusion работает в полноэкранном режиме.
Исправлена ошибка при зависании машины на несколько секунд при работе в Microsoft Excel.
Исправлена ошибка, когда использование USB-устройств на OS X 10.11 могло завалить виртуальную машину.
Исправлена ошибка, когда хостовая и гостевая раскладки клавиатуры (non-English) отличались при использовании VNC.
Исправлена ошибка подключения хоста к гостевой ОС, когда USB Attached SCSI (UAS) присоединен к порту USB 3.0 на Mac OS X 10.9 или более поздних версий.
Исправлено поведение, когда копирование большого файла с USB могло приводить к замораживанию процесса и в итоге его прерыванию по таймауту.
Посмотрите на список: большинство из этого - реально серьезные вещи. Что-то VMware в последнее время не радует своим подходом к тестированию продуктов.
Обновление VMware Fusion 8.1 бесплатно для всех пользователей восьмой версии, скачать его можно по этой ссылке.
Если вы не успели на этот вебинар, можно посмотреть его запись по этой ссылке:
Напомним, что StarWind HyperConverged Appliance - это программно-аппаратный комплекс, который строится все это на базе следующих аппаратных платформ (спецификации - тут):
VMware PowerCLI – это весьма мощный инструмент управления, а всё, что нужно сделать для начала работы с ним - это подключиться к серверу или серверам виртуальной инфраструктуры, которыми могут являться сервер управления vCenter Server, Linux vCenter Server Appliance (vCSA) или ESXi-хост.
Напомним, что vGate - это решение, которое позволяет защитить вашу виртуальную инфраструктуру Microsoft от несанкционированного доступа и безопасно сконфигурировать ее средствами политик безопасности.
Мероприятие пройдет 15 декабря в 11:00 по московскому времени. Вебинар проведет
Денис Полянский, менеджер по продукту компании «Код Безопасности».
В ходе вебинара будут подробно рассмотрены такие темы, как:
новый функционал продукта
редакции vGate и новая схема лицензирования
процессы обновления и перехода между редакциями
В конце вебинара в режиме чата участники смогут задать вопросы и оставить заявки на получение дополнительных материалов.
В блоге VMware появился интересный пост о производительности СУБД Microsoft SQL Server на облачной платформе VMware vCloud Air. Целью исследования было выявить, каким образом увеличение числа процессоров и числа виртуальных машин сказываются на увеличении производительности баз данных, которые во многих случаях являются бизнес-критичными приложениями уровня Tier 1 на предприятии.
В качестве тестовой конфигурации использовались виртуальные машины с числом виртуальных процессоров (vCPU) от 4 до 16, с памятью от 8 до 32 ГБ на одну ВМ, а на хост-серверах запускалось от 1 до 4 виртуальных машин:
На физическом сервере было 2 восьмиядерных процессора (всего 16 CPU), то есть можно было запустить до 16 vCPU в режиме тестирования линейного роста производительности (Hyper-Threading не использовался).
В качестве приложения использовалась база данных MS SQL с типом нагрузки OLTP, а сами машины размещались на хостинге vCloud Air по модели Virtual Private Cloud (более подробно об этом мы писали вот тут). Для создания стрессовой нагрузки использовалась утилита DVD Store 2.1.
Первый эксперимент. Увеличиваем число четырехпроцессорных ВМ на хосте от 1 до 4 и смотрим за увеличением производительности, выраженной в OPM (Orders Per Minute), то есть числе небольших транзакций в минуту:
Как видно, производительность показывает вполне линейный рост с небольшим несущественным замедлением (до 10%).
Второй эксперимент. Увеличиваем число восьмипроцессорных ВМ с одной до двух:
Здесь также линейный рост.
Замеряем производительность 16-процессорной ВМ и сводим все данные воедино:
Проседание производительности ВМ с 16 vCPU обусловлено охватом процессорами ВМ нескольких NUMA-узлов, что дает некоторые потери (да и вообще при увеличении числа vCPU удельная производительность на процессор падает).
Но в целом, как при увеличении числа процессоров ВМ, так и при увеличении числа виртуальных машин на хосте, производительность растет вполне линейно, что говорит о хорошей масштабируемости Microsoft SQL Server в облаке vCloud Air.
Кстати, если хочется почитать заказуху про то, как облака VMware vCloud Air уделывают Microsoft Azure и Amazon AWS, можно пройти по этим ссылкам:

 RSS
RSS






















 «За выдающийся вклад технического партнера в продвижение серверных систем NetApp» — такую
«За выдающийся вклад технического партнера в продвижение серверных систем NetApp» — такую 




















































{kind=link}

